CrashSight: A Phase-Aware, Infrastructure-Centric Video Benchmark for Traffic Crash Scene Understanding and Reasoning
1University of Wisconsin–Madison 2University of Wyoming 3Columbia University
Overview
Abstract
Cooperative autonomous driving requires traffic scene understanding from both vehicle and infrastructure perspectives. While vision-language models (VLMs) show strong general reasoning capabilities, their performance in safety-critical traffic scenarios remains insufficiently evaluated due to the ego-vehicle focus of existing benchmarks. To bridge this gap, we present CrashSight, a large-scale vision-language benchmark for roadway crash understanding using real-world roadside camera data. The dataset comprises 250 crash videos, annotated with 13K multiple-choice question-answer pairs organized under a two-tier taxonomy. Tier 1 evaluates the visual grounding of scene context and involved parties, while Tier 2 probes higher-level reasoning, including crash mechanics, causal attribution, temporal progression, and post-crash outcomes. We benchmark 8 state-of-the-art VLMs and show that, despite strong scene description capabilities, current models struggle with temporal and causal reasoning in safety-critical scenarios. We provide a detailed analysis of failure scenarios and discuss directions for improving VLM crash understanding. The benchmark provides a standardized evaluation framework for infrastructure-assisted perception in cooperative autonomous driving.
Highlights
- First Infrastructure-Side Crash VQA. 250 expert-annotated surveillance clips with phase-aware dense captions and 13K multiple-choice QA pairs across 7 categories.
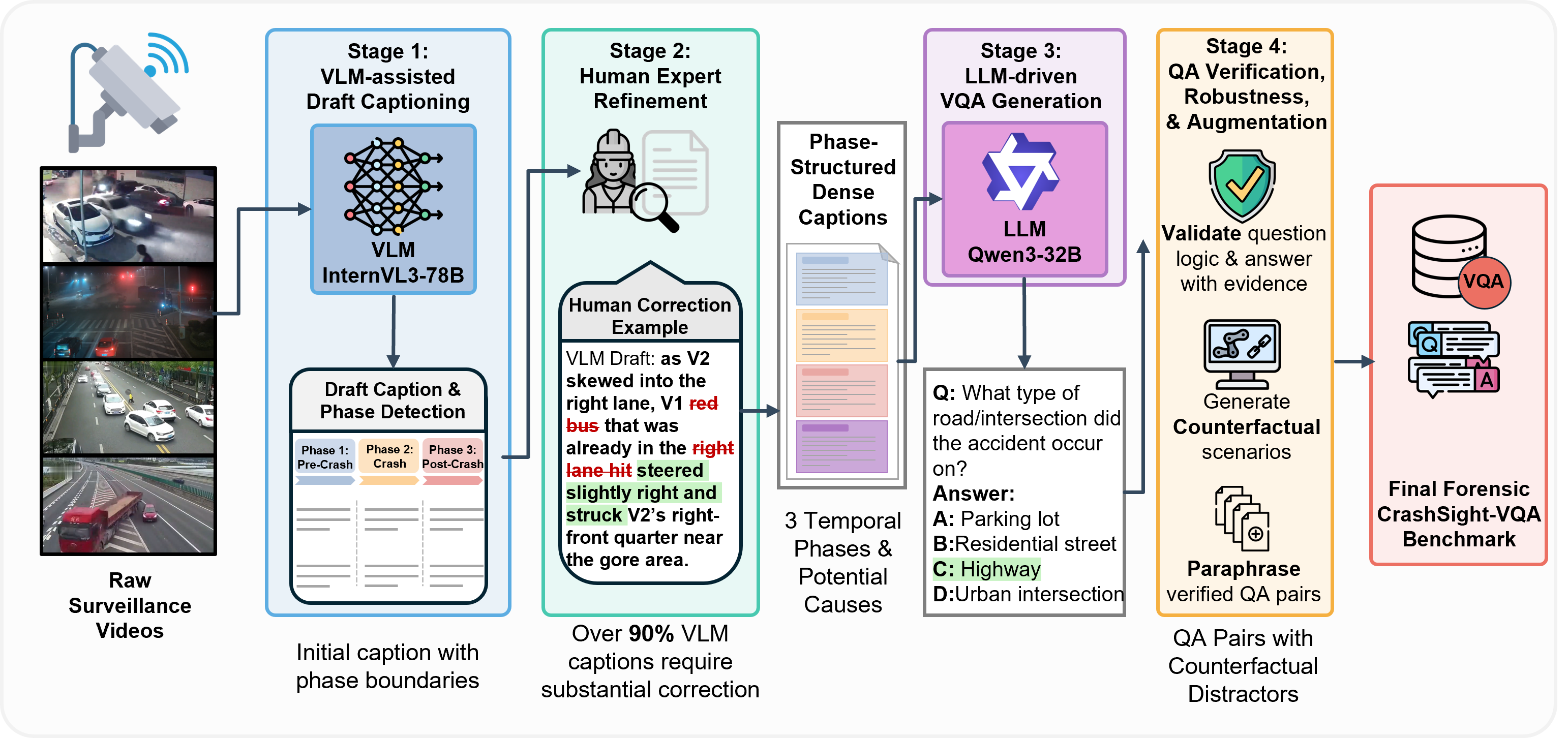
- 4-Stage Annotation Pipeline. VLM-assisted drafting → human expert refinement → LLM-driven VQA generation → verification & augmentation.
- +16.1% via Fine-Tuning. Domain-specific fine-tuning yields substantial gains; a 3B fine-tuned model surpasses all 8B zero-shot baselines.
- Systematic Error Taxonomy. Transition analysis traces persistent failures to visual token budget, frozen encoder, and pretraining distribution mismatch.
Benchmark Construction Pipeline
We develop a scalable 4-stage pipeline that transforms raw surveillance footage into a structured VQA benchmark. The pipeline combines VLM-assisted draft captioning with explicit phase boundaries, human expert refinement using a standardized correction template, LLM-driven QA generation with counterfactual distractors, and a final verification and augmentation pass. Approximately 90% of VLM drafts require substantial human correction, underscoring the necessity of expert oversight in safety-critical annotation.
QA Taxonomy
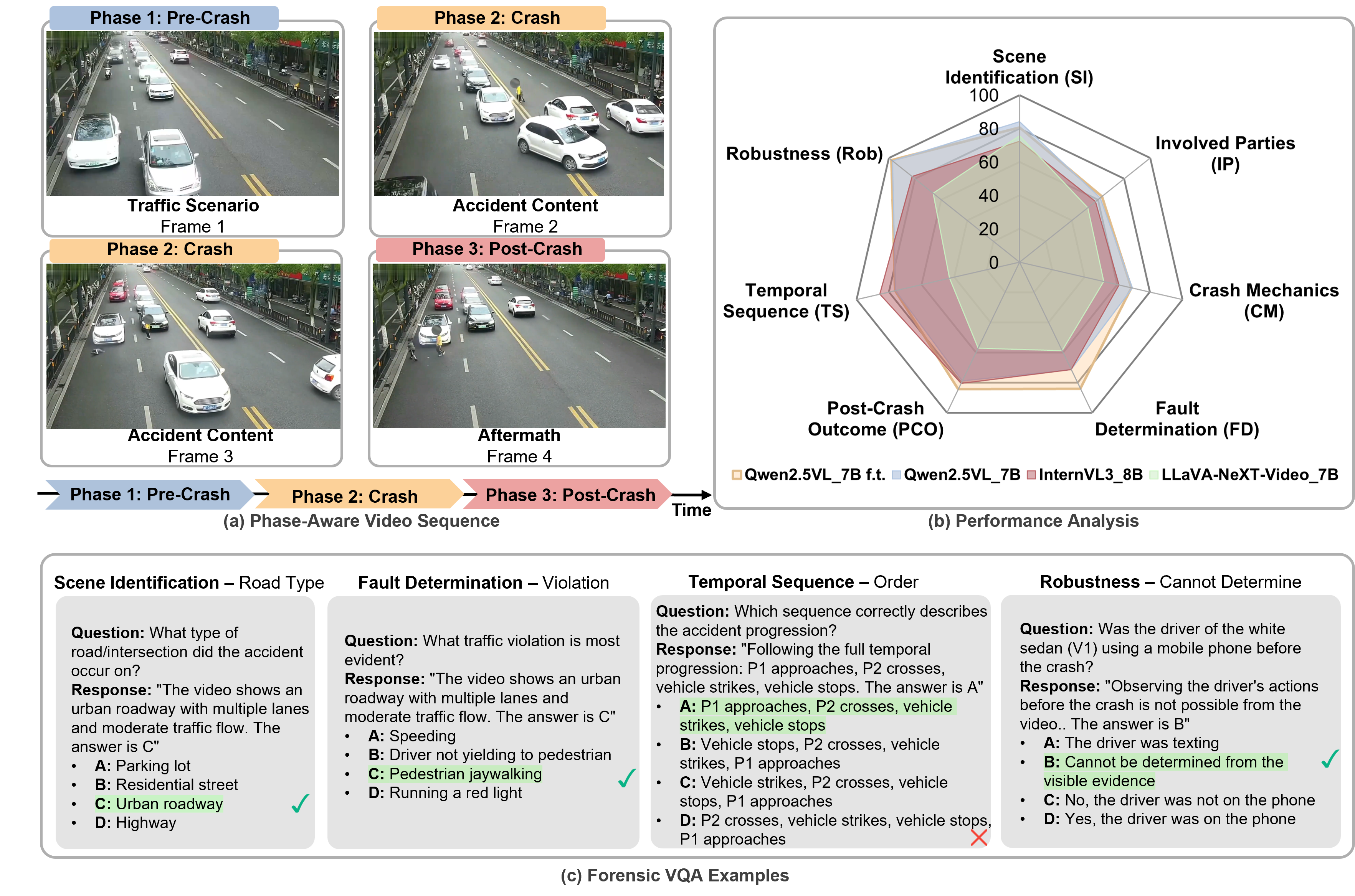
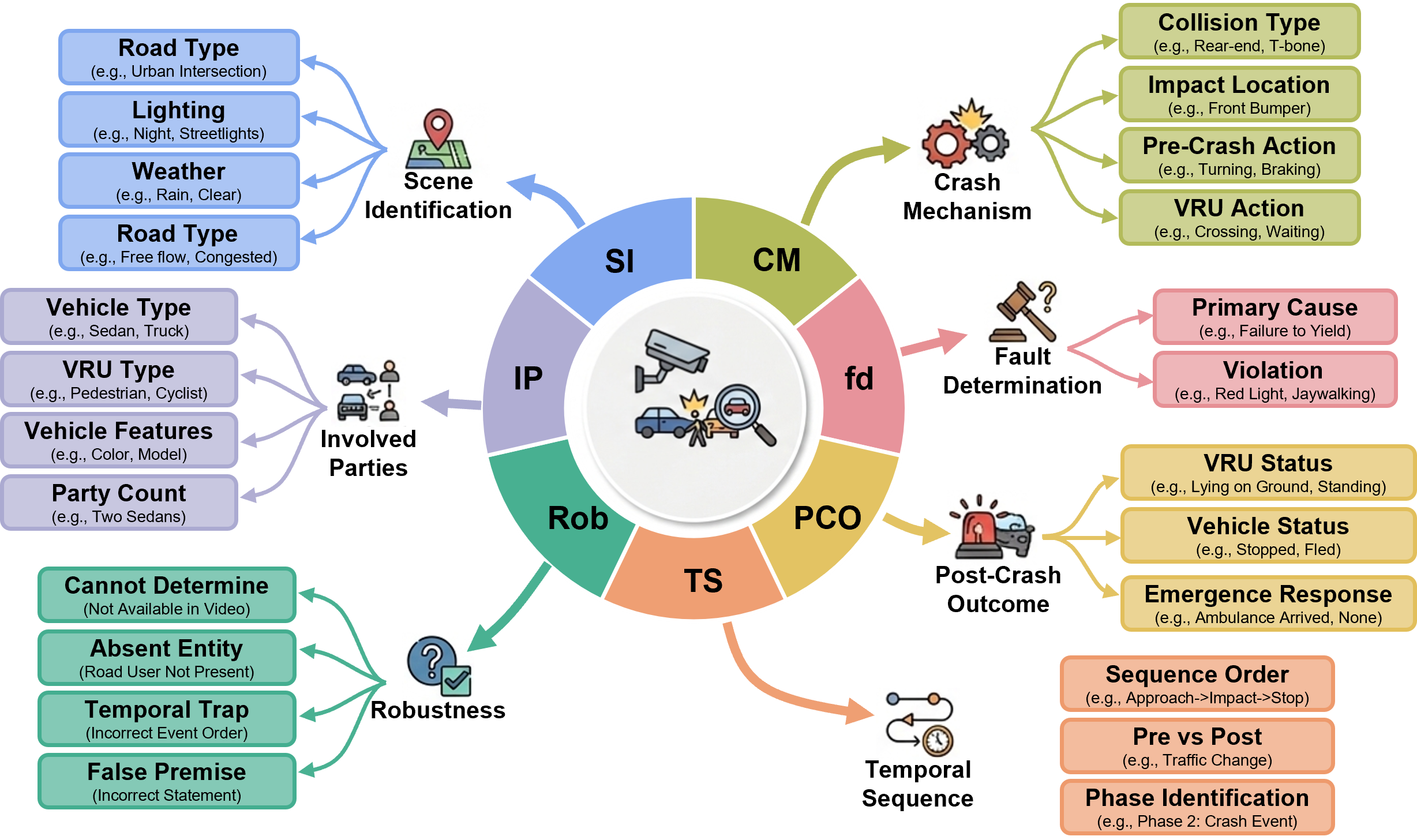
CrashSight organizes 13K QA pairs into a two-tier, seven-category taxonomy. Tier 1 (Crash Understanding) covers scene identification, involved parties, and post-crash outcomes through phase-local recognition. Tier 2 (Crash Reasoning) requires cross-phase temporal integration and causal inference for crash mechanics, fault determination, and temporal sequence tasks. A dedicated robustness category probes hallucination resistance with four distinct question types.
Video Demos
Example crash clips from CrashSight, showing phase-aware temporal decomposition from infrastructure cameras.
Side-impact collision at an urban intersection.
Rear-end collision on a multi-lane roadway.
Crash involving a vulnerable road user.
Multi-vehicle incident requiring temporal sequence reasoning.
Dataset Statistics
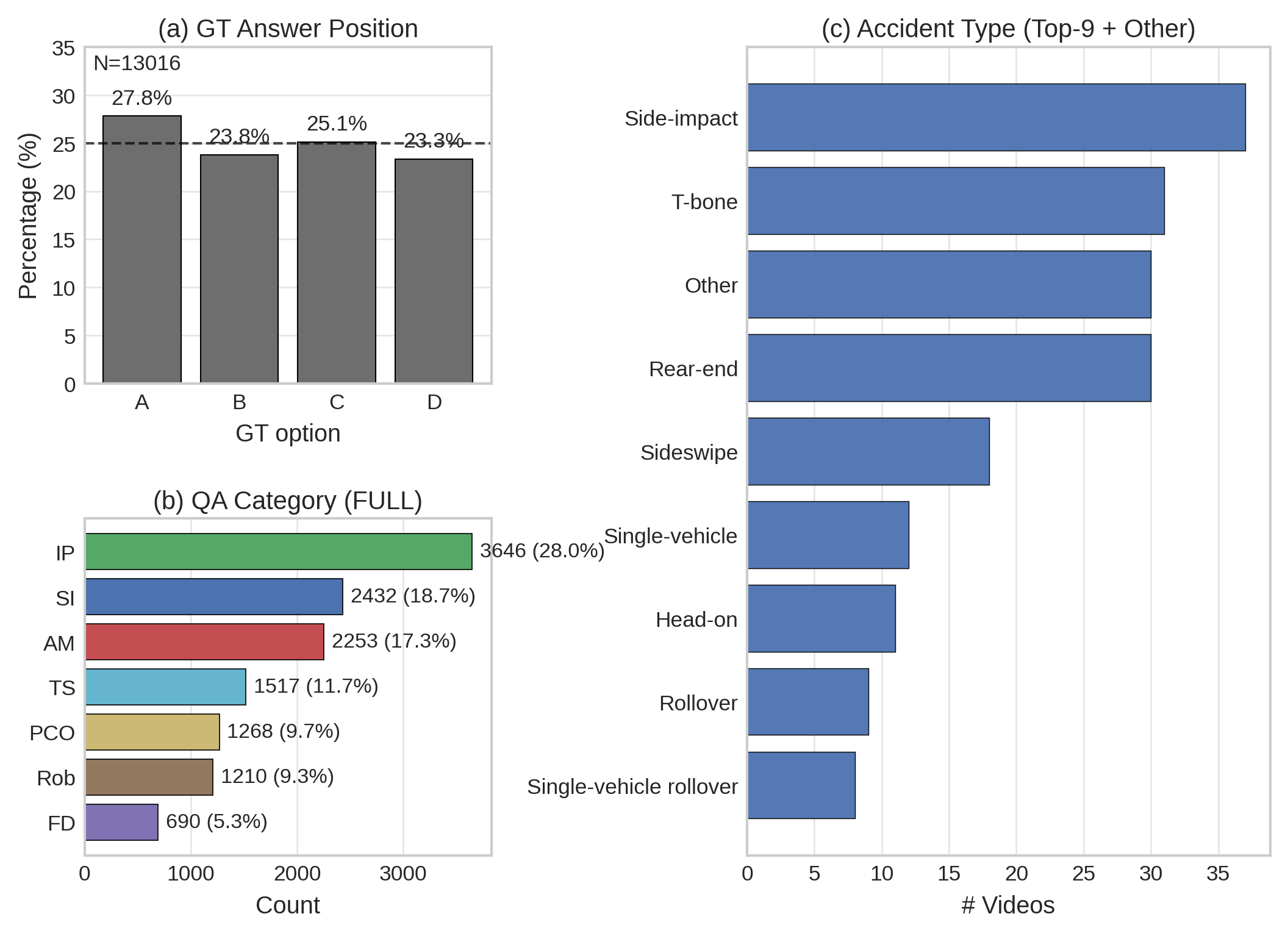
The benchmark contains 13,016 QA pairs with approximately uniform answer position distribution (23.3–27.8%) after option shuffling, eliminating position bias. Involved Parties (IP) is the largest category at 28.0% of all questions, reflecting the complexity of entity identification. Side-impact and T-bone collisions are the most prevalent accident types, consistent with the composition of the TAD source corpus.
Key Results
We benchmark 8 VLM configurations across four model families. Domain-specific fine-tuning yields up to +16.1 average accuracy improvement, with a fine-tuned 3B model (74.7%) surpassing all zero-shot baselines including InternVL3-8B (68.7%). A persistent human–AI gap of 18.3 points remains, concentrated in visually demanding categories such as Involved Parties and Crash Mechanics. Best zero-shot in underline, best overall in bold.
| Model | Size | SI | IP | CM | FD | PCO | TS | Rob | AVG |
|---|---|---|---|---|---|---|---|---|---|
| Zero-Shot Models | |||||||||
| LLaVA-OneVision | 0.5B | 59.4 | 36.0 | 36.7 | 50.6 | 48.0 | 52.4 | 18.9 | 41.5 |
| LLaVA-NeXT-Video | 7B | 75.5 | 52.3 | 51.6 | 58.6 | 57.1 | 42.9 | 66.1 | 58.6 |
| Qwen2.5-VL | 3B | 66.8 | 50.6 | 52.0 | 54.5 | 62.8 | 64.3 | 71.1 | 58.6 |
| Qwen2.5-VL | 7B | 67.7 | 51.9 | 55.4 | 66.7 | 74.2 | 66.7 | 73.3 | 62.9 |
| InternVL3 | 2B | 71.8 | 52.1 | 59.2 | 70.1 | 71.2 | 81.0 | 71.1 | 64.2 |
| InternVL3 | 8B | 72.4 | 58.1 | 61.1 | 71.3 | 80.3 | 85.7 | 82.2 | 68.7 |
| Fine-Tuned Models (Ours) | |||||||||
| Qwen2.5-VL (FT) | 3B | 84.0 | 61.6 | 69.3 | 71.3 | 78.8 | 76.0 | 97.2 | 74.7 |
| Qwen2.5-VL (FT) | 7B | 80.6 | 63.2 | 68.7 | 83.9 | 84.3 | 76.2 | 97.8 | 76.4 |
| Human Expert | – | 95.1 | 94.7 | 93.8 | 94.5 | 95.1 | 94.8 | 99.2 | 94.7 |
Qualitative Analysis
We identify two dominant persistent failure modes that fine-tuning cannot resolve. Temporal reasoning failures arise when sparse uniform frame sampling omits short but causally decisive pre-crash interactions, causing incomplete event reconstruction. Spatial grounding failures occur when bounded pixel resolution and a frozen visual encoder prevent the model from discriminating fine-grained entity details under oblique surveillance viewpoints.
Citation
@inproceedings{gan2026crashsight,
title={CrashSight: A Phase-Aware, Infrastructure-Centric Video Benchmark
for Traffic Crash Scene Understanding and Reasoning},
author={Gan, Rui and Ma, Junyi and Li, Pei and Yang, Xingyou
and Chen, Kai and Chen, Sikai and Ran, Bin},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision
and Pattern Recognition Workshops (CVPRW)},
year={2026}
}